Thuật toán Tarjan🏝️
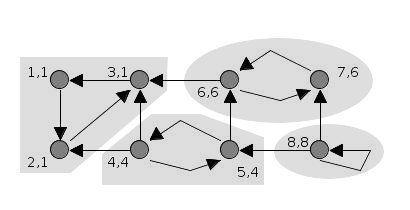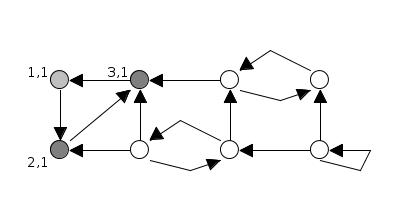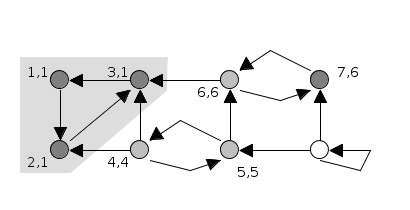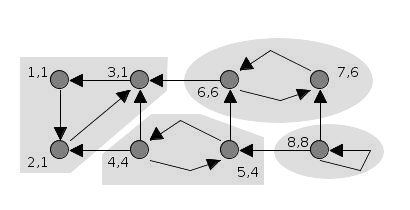 Minh họa thuật toán Tarjan
Minh họa thuật toán Tarjan
Dạng 1: Thành phần liên thông mạnh
Thuật toán Tarjan dựa trên việc duyệt theo chiều sâu (DFS) để tìm các Thành phần liên thông mạnh (TPLTM - Strongly Connected Components) với độ phức tạp $O(V + E)$.
- disc[u] (Discovery time): Thời điểm bắt đầu thăm đỉnh $u$.
- low[u]: Thời điểm thăm nhỏ nhất của một đỉnh mà từ $u$ (hoặc từ con cháu của $u$ trong cây DFS) có thể đi tới qua tối đa một cạnh ngược (back edge), với điều kiện đỉnh đó vẫn đang nằm trong Stack (onStack).
- Stack: Dùng để lưu trữ các đỉnh đang tạo thành một chu trình.
- Chốt (Root của TPLTM): Khi duyệt xong các nhánh con của $u$, nếu
low[u] == disc[u], $u$ chính là đỉnh chốt của một TPLTM.
Tại sao khi low[u] == disc[u] thì $u$ lại là chốt?
- Khi điều kiện này xảy ra, nghĩa là từ u và tất cả con cháu của u trong cây DFS không thể tìm được đường nào đi ngược lên các đỉnh tổ tiên của u. Do đó, u chính là chốt.
- Lúc này, mọi đỉnh nằm trên $u$ trong Stack (bao gồm cả $u$) sẽ được rút ra và gom thành một TPLTM độc lập.
Độ phức tạp: $O(V + E)$.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
int n, m;
const int limN = 1e4 + 5;
vector<int> adj[limN];
int timer = 0;
int disc[limN], low[limN];
bool onStack[limN];
stack<int> st;
///
vector<int> roots;
int scc = 0;
int scc_id[limN];
/// điều chỉnh tùy đề bài
void dfs(int u) {
disc[u] = low[u] = ++timer;
st.push(u); // đẩy u vô stack
onStack[u] = 1;
for(const int &v: adj[u]) {
if(!disc[v]) {
dfs(v);
minimize(low[u], low[v]); // nếu v có đường lên tổ tiên của u thì cập nhật
} else if(onStack[v]){
// u có cạnh ngược nên cập nhật low[u] qua cạnh ngược (back edge)
minimize(low[u], disc[v]);
}
}
if(low[u] == disc[u]) {
scc++;
roots.eb(u); // u là chốt
scc_id[u] = u;
while(1) { // reset stack
int v = st.top(); st.pop();
scc_id[v] = scc;
onStack[v] = 0;
if(u == v) break;
}
}
}
int main(void) {
cin >> n >> m;
FOR(i, 1, m + 1) {
int u, v; cin >> u >> v;
adj[u].eb(v);
}
FOR(u, 1, n + 1) {
if(!disc[u]) dfs(u);
}
...
}
Dạng 2: Kỹ thuật Nén đồ thị (Condensation Graph)
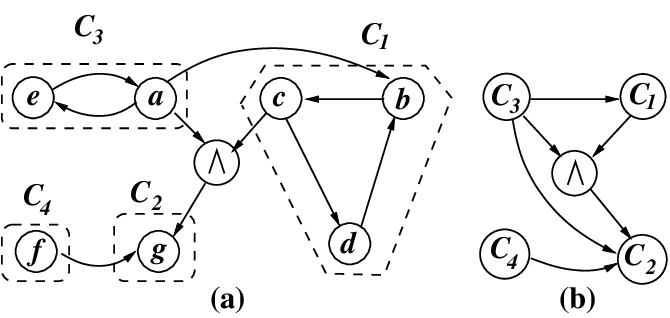 Ví dụ: $\quad$ $\quad$ (a) Đồ thị trước khi nén $\quad$ $\quad$ (b) Đồ thị sau khi nén
Ví dụ: $\quad$ $\quad$ (a) Đồ thị trước khi nén $\quad$ $\quad$ (b) Đồ thị sau khi nén
1. Tại sao phải Nén đồ thị?
Trong các bài toán trên đồ thị có hướng, nếu đồ thị là một DAG (Directed Acyclic Graph - Đồ thị có hướng không chu trình), ta có thể dễ dàng dùng Topo Sort và Quy hoạch động (DP) để giải quyết (ví dụ: tìm đường đi dài nhất, đếm số đường đi,…).
Tuy nhiên, nếu đồ thị có chu trình, việc dùng DP sẽ bị lặp vô tận. Do đó, ta cần “phá” chu trình bằng cách:
- Dùng Tarjan để tìm tất cả các SCC (các tập hợp đỉnh mà từ đỉnh này luôn có đường đi đến đỉnh kia).
- “Gom” mỗi SCC thành 1 Siêu đỉnh (Super-node).
- Tạo ra một đồ thị mới (chỉ chứa các Siêu đỉnh). Đồ thị mới này chắc chắn 100% là một DAG.
- Áp dụng DP hoặc thuật toán mong muốn trên DAG mới này.
2. Các bước Nén đồ thị
- Bước 1: Chạy DFS (Thuật toán Tarjan) trên đồ thị gốc để tìm các SCC. Gán cho mỗi đỉnh $u$ một ID của khối SCC chứa nó, gọi là
scc_id[u]. - Bước 2: Duyệt qua mọi cạnh $(u, v)$ của đồ thị gốc.
- Nếu $u$ và $v$ nằm ở 2 SCC khác nhau (tức là
scc_id[u] != scc_id[v]), ta thêm một cạnh có hướng từ siêu đỉnhscc_id[u]sang siêu đỉnhscc_id[v]trên đồ thị mới (DAG).
- Nếu $u$ và $v$ nằm ở 2 SCC khác nhau (tức là
- Bước 3: Tính trọng số cho siêu đỉnh và chạy DP/Topo Sort trên đồ thị DAG vừa tạo..
- Lưu ý: Tùy vào yêu cầu bài toán, trọng số có thể là tổng giá trị, số lượng đỉnh trong SCC, hoặc giá trị lớn nhất/nhỏ nhất.
Thuật toán Tarjan gán
scc_idtheo thứ tự topo ngược vớiscc_id = 1luôn là điểm cuối (đỉnh trũng - sink) vàscc_id = sccluôn là điểm đầu (đinh nguồn - source)
$\Rightarrow$ Duyệt từ 1 $\to$ scc là thứ tự topo ngược.
$\Rightarrow$ Duyệt từ scc $\to$ 1 là thứ tự topo xuôi.
(Khái niệm đỉnh nguồn & đỉnh trũng xem dạng 3 để hiểu rõ)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
int n, m;
const int limN = 1e5 + 5;
vector<int> adj[limN];
int A[limN];
int timer = 0;
int disc[limN], low[limN];
stack<int> st;
int onStack[limN];
int scc = 0;
int scc_id[limN];
void dfs(int u) {
disc[u] = low[u] = ++timer;
st.push(u);
onStack[u] = 1;
for(const int &v: adj[u]) {
if(!disc[v]) {
dfs(v);
minimize(low[u], low[v]);
} else if(onStack[v]){
minimize(low[u], disc[v]);
}
}
if(disc[u] == low[u]) {
scc++;
while(1) {
int v = st.top(); st.pop();
scc_id[v] = scc;
onStack[v] = 0;
if(v == u) break;
}
}
}
vector<int> dag_adj[limN]; // đồ thị dag sau khi nén
ll weight_scc[limN]; // trọng số (tổng A[i]) của mỗi siêu đỉnh
ll dp[limN];
int main(void) {
cin >> n >> m;
FOR(i, 1, n + 1) {
cin >> A[i];
}
FOR(i, 1, m + 1) {
int u, v; cin >> u >> v;
adj[u].eb(v);
}
// bước 1: chạy tarjan tìm scc_id
FOR(u, 1, n + 1) {
if(!disc[u]) dfs(u);
}
// bước 2: nén đồ thị
FOR(u, 1, n + 1) { // duyệt qua mọi cạnh (u,v)
if(!scc_id[u]) continue;
for(const int &v: adj[u]) {
// nếu u và v thuộc 2 scc khác nhau, tạo cạnh nối 2 siêu đỉnh
if(scc_id[v] && scc_id[u] != scc_id[v]) {
dag_adj[scc_id[u]].eb(scc_id[v]);
}
}
}
// bước 3: giải quyết bài toán...
}
Ví dụ bước 3:
1
2
3
4
5
6
7
8
9
10
11
12
13
// bước 3: giải quyết bài toán
FOR(u, 1, n + 1) {
weight_scc[scc_id[u]] += A[u]; // tính trọng số cho mỗi siêu đỉnh scc
}
ll res = 0; // dp[u] = max(dp[v]) + weight
FOR(u, 1, scc + 1) { // duyệt theo thứ tự topo ngược để tính trước v
maximize(dp[u], weight_scc[u]); // lấy chính nó làm điểm bắt đầu
for(const int &v: dag_adj[u]) {
maximize(dp[u], dp[v] + weight_scc[u]); // lấy v tốt nhất
}
maximize(res, dp[u]);
}
cout << res;
3. Kỹ thuật phẳng hóa và mở rộng với bài toán lưới 2D
Kỹ thuật phẳng hóa
Để làm việc với các thuật toán đồ thị 1D như Tarjan, trước hết nên chuyển tọa độ $(x, y)$ của lưới $N \times M$ thành một ID duy nhất như sau:
- (x, y) là 0-index:
- Chuyển thuận: $ID = x \times M + y$
- Chuyển ngược (Để debug):
- $x = ID / M$
- $y = ID \% M$
- Phạm vi ID: $0 \le ID < N \times M$.
- (x, y) là 1-index:
- Chuyển thuận: $ID = (x - 1) \times M + y$
- Chuyển ngược (Để debug):
- $x = (ID - 1) / M + 1$
- $y = (ID - 1) \% M + 1$
- Phạm vi ID: $1 \le ID \le N \times M$
(Trong đó $M$ là số lượng cột)
Bài toán kinh điển
Dấu hiệu nhận biết:
“Rôbô được đi qua một ô nhiều lần… lợi nhuận thu được bằng chỉ số… sau này không thể đạt thêm lợi nhuận”: Nếu đồ thị có một chu trình (có thể đi lòng vòng và quay lại ô cũ), ta có quyền đi càn quét và thu hoạch toàn bộ trái cây của mọi ô nằm trong chu trình đó. Một tập hợp các ô đi qua đi lại được với nhau chính là một Thành phần liên thông mạnh (SCC).
Bình thường đi hướng Đông và Nam trên lưới thì nó mặc định là một DAG (không thể có chu trình). Nhưng đề bài chêm thêm “ô đặc biệt” cho phép đi hướng Tây hoặc Bắc. Lập tức, các cạnh ngược (back-edges) xuất hiện, sinh ra chu trình và phá vỡ DAG.
Tóm lại:
- Mỗi ô trên lưới (trừ ô có cây dừa): 1 đỉnh trong đồ thị
- Đi hướng Đông và Nam trên lưới: forward edge
- Đi hướng Tây và Bắc trên lưới: back edge $\Rightarrow$ sự xuất hiện này tạo ra chu trình.
$\Rightarrow \quad$ Cần đưa về DAG.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
//...
vector<int> dag_adj[limN];
ll weight_scc[limN];
ll dp[limN];
inline int getId(int x, int y) {
return (x - 1) * m + y;
}
int A[limN];
int di[2] = {1, 0};
int dj[2] = {0, 1};
int main(void) {
cin >> n >> m;
char grid[n + 1][m + 1];
FOR(i, 1, n + 1) {
FOR(j, 1, m + 1) {
cin >> grid[i][j];
auto id = getId(i, j);
A[id] = (isdigit(grid[i][j])? grid[i][j] - '0': 0);
FOR(k, 0, 2) {
int ni = i + di[k];
int nj = j + dj[k];
int nid = getId(ni, nj);
if(ni <= n && nj <= m && grid[i][j] != '#') {
adj[id].eb(nid);
}
}
if(grid[i][j] == 'W') { // tây
int ni = i;
int nj = j - 1;
int nid = getId(ni, nj);
if(ni >= 1 && nj >= 1 && grid[i][j] != '#') {
adj[id].eb(nid);
}
}
else if(grid[i][j] == 'N') { // bắc
int ni = i - 1;
int nj = j;
int nid = getId(ni, nj);
if(ni >= 1 && nj >= 1 && grid[i][j] != '#') {
adj[id].eb(nid);
}
}
}
}
// bước 1: chạy tarjan tìm scc_id
FOR(u, 1, n * m + 1) {
if(!disc[u]) dfs(u);
}
// bước 2: nén đồ thị
FOR(u, 1, n * m + 1) {
if(!scc_id[u]) continue;
for(const int &v: adj[u]) {
if(scc_id[v] && scc_id[u] != scc_id[v]) {
dag_adj[scc_id[u]].eb(scc_id[v]);
}
}
weight_scc[scc_id[u]] += A[u];
}
// bước 3: giải quyết bài toán (dp trên dag)
FOR(u, 1, scc + 1) {
maximize(dp[u], weight_scc[u]);
for(const int &v: dag_adj[u]) {
maximize(dp[u], dp[v] + weight_scc[u]);
}
}
int start = getId(1, 1);
if(!scc_id[start]) return cout << 0, 0;
cout << dp[scc_id[start]];
}
Dạng 3: Bài toán Đỉnh nguồn (Source) & Đỉnh trũng (Sink)
1. Đỉnh Nguồn (Source) (In-degree = 0)
Định nghĩa: Là đỉnh không có mũi tên nào trỏ vào nó. Chỉ có mũi tên đi ra.
Hình ảnh: Nó giống như một “nguồn nước” (suối nguồn). Nước từ đây chảy đi các nơi khác, nhưng không có dòng nước nào chảy ngược về nó được.
Ví dụ:
Nếu một người si tình là đỉnh nguồn, không ai có thể yêu họ (vì không có cửa).
Trong một công ty, Sếp tổng là đỉnh nguồn (ra lệnh nhưng không ai ra lệnh cho sếp).
2. Đỉnh Trũng (Sink) (Out-degree = 0)
Định nghĩa: Là đỉnh không có mũi tên nào đi ra khỏi nó. Chỉ có các mũi tên trỏ vào.
Hình ảnh: Nó giống như một “hố thu nước” (cái phễu hoặc bồn chứa). Nước chảy vào đây là “kẹt” luôn, không đi đâu được nữa.
Ví dụ:
- Nếu một nhóm đỉnh (TPLTM) là đỉnh trũng, nghĩa là một khi đã đi vào vùng này, bạn không thể thoát ra để đi sang vùng khác.
- Nhân viên thực thi cuối cùng là đỉnh trũng (nhận lệnh, làm báo cáo kết thúc công việc chứ không ra lệnh cho ai khác).
- Nếu cả đồ thị chỉ có duy nhất một vùng trũng, thì mọi con đường từ các nơi khác cuối cùng sẽ bị hút hết về vùng trũng này. Do đó, vùng trũng đó chính là Thủ đô.
3. Các bước giải quyết
Bước 1: Tìm các Thành phần liên thông mạnh (SCC) bằng Tarjan (Dạng 1)
Bước 2: Nén đồ thị thành DAG (Directed Acyclic Graph) (Dạng 2)
Bước 3: Đếm Bán bậc vào in_deg (In-degree) và Bán bậc ra out_deg (Out-degree) của các Siêu đỉnh trên đồ thị DAG mới.
Bước 4: Trả lời câu hỏi bài toán: Dựa vào số lượng Siêu đỉnh có in_deg = 0 (Đỉnh Nguồn) hoặc out_deg = 0 (Đỉnh Trũng).
| Thuật ngữ | Bán bậc | Đặc điểm |
|---|---|---|
| Đỉnh Nguồn | $In = 0$ | Không ai đến được nó. |
| Đỉnh Trũng | $Out = 0$ | Nó không đi được đâu nữa. |
4. Ý tưởng của việc nén đồ thị rồi mới tìm Nguồn/Trũng
Nếu để đồ thị nguyên bản có chu trình (ví dụ $A \to B$, $B \to C$, $C \to A$), ta sẽ thấy:
- $A$ có mũi tên vào từ $C \Rightarrow In \neq 0$.
- $A$ có mũi tên ra tới $B \Rightarrow Out \neq 0$.
$\Rightarrow \quad$ $A, B, C$ đều không phải nguồn, cũng không phải trũng.
Nhưng thực tế, nhóm ${A, B, C}$ này lại là một cụm cô lập nếu không có ai khác trỏ vào nó. Khi đó, ta dùng Tarjan để nén $A, B, C$ thành một Siêu đỉnh $X$:
Nếu không có đỉnh bên ngoài nào trỏ vào $A, B,$ hay $C$, thì Siêu đỉnh $X$ sẽ có $In-degree = 0$.
Lúc này, $X$ trở thành Đỉnh nguồn của đồ thị mới (DAG).
5. Một số bài toán kinh điển
- Ta cần chọn ra các đỉnh để bắt đầu truyền tin sao cho tin đi đến được mọi nơi.
- Nếu một người có
in > 0, nó sẽ được nhận tin từ cụm khác truyền tới. Nếu một người cóin = 0(đỉnh nguồn), KHÔNG ai có thể truyền tin cho nó, bắt buộc ta phải chọn 1 người trong cụm này để khởi đầu.
Thủ đô phải là nơi mà ai cũng có thể đi đến. Tức là mọi luồng đi cuối cùng đều phải đổ về Siêu đỉnh này $\Rightarrow$ Nó phải là Siêu đỉnh có
out = 0(đỉnh trũng) (không đi ra ngoài nữa, chỉ nhận vào).*Lưu ý: Nếu đồ thị DAG có từ 2 Siêu đỉnh trở lên có
out = 0(đỉnh trũng), thì 2 cụm này không thể đi đến nhau được $\Rightarrow$ Sẽ không có thủ đô nào cả. Chỉ khi có duy nhất 1 Siêu đỉnh cóout = 0(đỉnh trũng), thì tất cả các đỉnh nằm trong TPLTM đó đều là thủ đô.
Mở rộng: Cần thêm ít nhất bao nhiêu cạnh để một đồ thị có hướng trở thành Liên thông mạnh?
$\Rightarrow \quad ans = \max$(số đỉnh nguồn, số đỉnh trũng) khi|SCC| > 1.
$\Rightarrow \quad ans = 0$ khi|SCC| = 1.
Dạng 4: 2-SAT (2-Satisfiability)
1. Định nghĩa
2-SAT (2-Satisfiability) là bài toán kiểm tra xem có tồn tại một cách gán giá trị Đúng (True) hoặc Sai (False) cho các biến logic sao cho một tập hợp các điều kiện cho trước đều được thỏa mãn hay không.
Trong lập trình thi đấu, đây là “vũ khí” cực mạnh để giải quyết các bài toán dạng “chọn một trong hai” hoặc “loại trừ lẫn nhau”.
2. Cấu trúc của 2-SAT
Một bài toán 2-SAT bao gồm:
- Biến số: $x_1, x_2, \dots, x_n$ (mỗi biến chỉ có thể là $0$ hoặc $1$).
- Điều kiện (Clauses): Mỗi điều kiện là phép OR ($\lor$) của đúng 2 biến (hoặc phủ định của chúng).
- Mục tiêu: Tìm một bộ giá trị sao cho:
Tại sao lại gọi là “2”-SAT? Vì mỗi dấu ngoặc chỉ chứa đúng 2 biến. Nếu là 3 biến (3-SAT), bài toán sẽ trở thành “siêu khó” (NP-complete) và không có thuật toán tối ưu để giải nhanh như 2-SAT.
3. Chuyển từ Logic sang Đồ thị (Implication Graph)
Đây là bước biến một bài toán logic thuần túy thành bài toán đồ thị. Ta dựa trên tính chất:
\[(A \lor B) \equiv (\neg A \implies B) \land (\neg B \implies A)\]- Đỉnh: Với mỗi biến $x_i$, ta tạo ra 2 đỉnh trên đồ thị: một đỉnh đại diện cho $x_i$ và một đỉnh đại diện cho $\neg x_i$.
- Cạnh (Cung suy ra): Với mỗi điều kiện $(A \lor B)$, ta vẽ hai mũi tên:
- $\neg A \to B$: “Nếu không chọn $A$, thì bắt buộc phải chọn $B$”.
- $\neg B \to A$: “Nếu không chọn $B$, thì bắt buộc phải chọn $A$”.
4. Khi nào thì bài toán Vô nghiệm?
Bài toán 2-SAT sẽ vô nghiệm khi và chỉ khi:
Tồn tại một biến $x_i$ sao cho từ $x_i$ ta có thể đi đến $\neg x_i$ VÀ từ $\neg x_i$ cũng có thể đi ngược lại $x_i$ thông qua các mũi tên suy luận.
Nói theo ngôn ngữ đồ thị: $x_i$ và $\neg x_i$ nằm trong cùng một Thành phần liên thông mạnh (SCC).
- Logic: Nếu $x_i \implies \neg x_i$, điều đó có nghĩa là nếu $x_i$ đúng thì nó cũng phải sai (vô lý). Nếu cả hai chiều đều xảy ra, ta rơi vào một vòng lặp mâu thuẫn không thể tháo gỡ.
5. Một số patterns và dấu hiệu nhận biết 2-SAT
| Yêu cầu thực tế | Công thức 2-SAT | Hệ quả 1 ($\neg L_1 \rightarrow L_2$) | Hệ quả 2 ($\neg L_2 \rightarrow L_1$) | Giải thích dân dã |
|---|---|---|---|---|
| Ít nhất 1 trong 2 (OR) | $(x_A \lor x_B)$ | $\neg x_A \Rightarrow x_B$ | $\neg x_B \Rightarrow x_A$ | Không chọn A thì buộc phải chọn B. |
| Loại trừ lẫn nhau (NAND) | $(\neg x_A \lor \neg x_B)$ | $x_A \Rightarrow \neg x_B$ | $x_B \Rightarrow \neg x_A$ | Đã chọn A thì cấm chọn B (và ngược lại). |
| Ràng buộc kéo theo (IF–THEN) | $(\neg x_A \lor x_B)$ | $x_A \Rightarrow x_B$ | $\neg x_B \Rightarrow \neg x_A$ | Có A là phải có B; Không có B thì chắc chắn không có A. |
| Bắt buộc chọn A | $(x_A \lor x_A)$ | $\neg x_A \Rightarrow x_A$ | — | Nếu giả sử “Không A” thì dẫn đến mâu thuẫn, nên A phải đúng. |
| Bắt buộc bỏ A | $(\neg x_A \lor \neg x_A)$ | $x_A \Rightarrow \neg x_A$ | — | Nếu giả sử “Có A” thì dẫn đến mâu thuẫn, nên A phải sai. |
| Cùng sống cùng chết (IFF) | $(x_A \lor \neg x_B)\land(\neg x_A \lor x_B)$ | $x_B \Rightarrow x_A$ | $x_A \Rightarrow x_B$ | A có thì B có, A mất thì B mất (tương đương $x_A = x_B$). |
| Chọn đúng 1 trong 2 (XOR) | $(x_A \lor x_B)\land(\neg x_A \lor \neg x_B)$ | $\neg x_A \Rightarrow x_B$ | $x_A \Rightarrow \neg x_B$ | Không được chọn cả hai, cũng không được bỏ cả hai. |
Để một bài toán được coi là 2-SAT, nó phải thỏa mãn hai điều kiện cần và đủ sau:
1. Biến số nhị phân: Mỗi đối tượng chỉ có đúng 2 khả năng xảy ra (Đúng/Sai, A/B, Bật/Tắt).
2. Ràng buộc cặp (Pairwise): Các điều kiện hạn chế chỉ xảy ra giữa tối đa 2 biến với nhau.
6. Giải 2-SAT sử dụng thuật toán Tarjan
Để giải 2-SAT, ta cần làm 2 việc: Kiểm tra xem có nghiệm hay không, và nếu có thì nghiệm đó là gì (biến nào True, biến nào False). Thuật toán Tarjan xử lý mượt mà cả hai việc này:
1. Dựng đồ thị
Giả sử có $N$ biến. Ta mở rộng thành $2N$ đỉnh. Đỉnh $i$ đại diện cho $X_i$ (mang giá trị True), đỉnh $i+N$ đại diện cho $\neg X_i$ (mang giá trị False). Với điều kiện $(A \lor B)$, ta thêm 2 cung: $\neg A \to B$ và $\neg B \to A$.
Hàm
getId(int x): Trả về ID của đỉnh tương ứng với giá trị logic $x$.
- Nếu $x > 0$: Nghĩa là biến $x$ đang ở trạng thái khẳng định ($X_x$) $\Rightarrow$ Trả về chính nó (ID nằm trong khoảng $1 \dots n$).
- Nếu $x < 0$: Nghĩa là biến $x$ đang ở trạng thái phủ định ($\neg X_{|x|}$). $\Rightarrow$ Trả về $-x + n$ (tương đương $|x| + n$, ID nằm trong khoảng $n+1 \dots 2n$).
Ví dụ ($n=10$):
getId(3)$\to$ trả về đỉnh 3 (Đại diện cho $X_3$ là TRUE).getId(-3)$\to$ trả về đỉnh 13 (Đại diện cho $X_3$ là FALSE).
Hàm
getNeg(int x): Trả về ID của đỉnh đối lập với giá trị logic $x$. Đây là hàm cực kỳ quan trọng để xây dựng các cạnh suy diễn ($\neg A \to B$).
- Nếu $x > 0$ (đang là Khẳng định): Ta cần tìm Phủ định của nó $\to$ Trả về $x + n$.
- Nếu $x < 0$ (đang là Phủ định): Ta cần tìm Khẳng định của nó $\to$ Trả về $-x$ (tức là $|x|$).
Ví dụ ($n=10$):
- getNeg(3) $\to$ trả về 13 (Phủ định của “3 TRUE” là “3 FALSE”).
- getNeg(-3) $\to$ trả về 3 (Phủ định của “3 FALSE” là “3 TRUE”).
1
2
adj[getNeg(u)].eb(getId(v)); // Nếu phủ định của u xảy ra, thì v phải xảy ra
adj[getNeg(v)].eb(getId(u)); // Nếu phủ định của v xảy ra, thì u phải xảy ra
2. Kiểm tra vô nghiệm
Chạy Tarjan tìm SCC. Nếu tồn tại biến $i$ mà đỉnh $i$ và đỉnh $i+N$ có cùng scc_id (scc_id[i] == scc_id[i+N]), bài toán vô nghiệm. Vì $X \implies \dots \implies \neg X$ và $\neg X \implies \dots \implies X$ tạo ra một vòng lặp nghịch lý.
3. Khôi phục nghiệm
Tarjan duyệt xong một SCC và gán ID cho nó khi nó không thể đi tới một SCC nào chưa được xử lý. Điều này có nghĩa là các SCC được gán ID theo thứ tự ngược của Topo. (Như dạng 3 đã đề cập)
- Trong đồ thị suy luận, ta luôn phải ưu tiên chọn các đỉnh nằm “cuối” đường đi (sink) để tránh việc chọn đỉnh đầu nhưng lại suy ra một điều kiện sai ở cuối.
- Do ID của Tarjan là ngược Topo, nên đỉnh nào có
scc_idnhỏ hơn sẽ nằm ở cuối hơn. - Vì vậy, ta chỉ cần phép gán đơn giản:
ans[i] = (scc[i] < scc[i+N]).
4. Bài toán ví dụ
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//...
inline int getId(int x) {
return x > 0? x: -x + n;
}
inline int getNeg(int x) {
return x > 0? x + n: -x;
}
int main(void) {
// A or B = (not A -> B) and (not B -> A)
cin >> m >> n;
FOR(i, 1, m + 1) {
int u, v; cin >> u >> v;
adj[getNeg(u)].eb(getId(v));
adj[getNeg(v)].eb(getId(u));
}
FOR(u, 1, (n << 1)) {
if(!disc[u]) dfs(u); // chạy tarjan
}
vector<int> res;
FOR(u, 1, n + 1) {
if(scc_id[u] == scc_id[u + n]) return cout << "NO", 0;
if(scc_id[u] < scc_id[u + n]) res.eb(u);
}
cout << "YES" << nl << sz(res) << nl;
for(const int &x: res) cout << x << ' ';
}
Dạng 5: Khớp và cầu
1. Định nghĩa
Trong đồ thị vô hướng, một đỉnh được gọi là đỉnh khớp nếu như loại bỏ đỉnh này và các cạnh liên thuộc với nó ra khỏi đồ thị thì số thành phần liên thông của đồ thị tăng lên.
Trong đồ thị vô hướng, một cạnh được gọi là cạnh cầu nếu như loại bỏ cạnh này ra khỏi đồ thị thì số thành phần liên thông của đồ thị tăng lên.
Để tối ưu nhất có thể, ta sẽ sử dụng thuật toán Tarjan để tìm cầu và khớp trong $O(V + E)$, với định nghĩa sau:
- disc[u] (Discovery time): Thời điểm bắt đầu thăm đỉnh $u$.
- low[u]: Thời điểm thăm nhỏ nhất của một đỉnh mà từ $u$ (hoặc từ con cháu của $u$ trong cây DFS) có thể đi tới qua tối đa một cạnh ngược (back edge)
2. Khớp
Nguyên lý hoạt động:
- Điều kiện 1: Nếu $u$ là gốc của cây DFS và có nhiều hơn 1 nhánh con độc lập
(child > 1), $u$ là khớp. - Điều kiện 2: Nếu $u$ không phải gốc và tồn tại một nhánh con $v$ sao cho
disc[u] <= low[v](tức là từ $v$ không có cách nào vòng ngược lên được tổ tiên của $u$), thì $u$ là khớp.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
const int limN = 1005;
vector<int> adj[limN];
int n, m;
int disc[limN], low[limN];
set<int> ap; // lưu các khớp, dùng set để tránh trùng lặp
int timer = 0;
void dfs(int u, int p) {
disc[u] = low[u] = ++timer;
int child = 0;
for(const int &v : adj[u]) {
if(v == p) continue;
if(disc[v] == 0) {
child++;
dfs(v, u);
minimize(low[u], low[v]); // nếu v có đường lên tổ tiên của u thì cập nhật
// điều kiện khớp 2: u không phải root và v không có đường nào lên tổ tiên của u
if(p && disc[u] <= low[v]) {
ap.insert(u);
}
} else {
// u có cạnh ngược nên cập nhật low[u] qua cạnh ngược (back edge)
minimize(low[u], disc[v]);
}
}
if(!p && child > 1) { // điều kiện khớp 1: u là gốc và có nhiều hơn 1 con
ap.insert(u);
}
}
int main(void) {
cin >> n >> m;
FOR(i, 1, m + 1) {
int u, v; cin >> u >> v;
adj[u].eb(v);
adj[v].eb(u);
}
FOR(u, 1, n + 1) {
if(!disc[u]) dfs(u, 0);
}
cout << sz(ap);
}
3. Cầu
Nguyên lý hoạt động:
- Điều kiện: Cạnh $(u, v)$ là cầu khi và chỉ khi từ nhánh con $v$ không có bất kỳ cạnh ngược nào nối về $u$ hoặc các tổ tiên của $u$. Điều này tương đương với điều kiện
disc[u] < low[v].
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
typedef pair<int, int> ii;
int n, m;
const int limN = 1005;
vector<int> adj[limN];
int disc[limN], low[limN];
int timer = 0;
vector<ii> bridges; // lưu các cầu
void dfs(int u, int p) {
disc[u] = low[u] = ++timer;
for(const int &v : adj[u]) {
if(v == p) continue;
if(disc[v] == 0) {
dfs(v, u);
minimize(low[u], low[v]); // nếu v có đường lên tổ tiên của u thì cập nhật
if(disc[u] < low[v]) { // điều kiện cầu: u và v không có cạnh ngược
bridges.eb(u, v);
}
} else {
// u có cạnh ngược nên cập nhật low[u] qua cạnh ngược (back edge)
minimize(low[u], disc[v]);
}
}
}
int main(void) {
cin >> n >> m;
FOR(i, 1, m + 1) {
int u, v; cin >> u >> v;
adj[u].eb(v);
adj[v].eb(u);
}
FOR(u, 1, n + 1) {
if(!disc[u]) dfs(u, 0);
}
cout << sz(bridges);
}
3. Bẫy đa cạnh (multi-graph)
Giả sử giữa đỉnh $u$ và $v$ có 2 cạnh nối: Cạnh số 1 và Cạnh số 2.
- Ta đang đứng ở $u$, đi sang $v$ thông qua Cạnh 1.
- Khi đệ quy duyệt các đỉnh kề của $v$, ta sẽ thấy đỉnh $u$.
- Nếu dùng
if(v == p) continue;, code sẽ bỏ qua toàn bộ các cạnh nối về u, gồm cả Cạnh 1 và Cạnh 2.
$\Rightarrow \quad$ Hậu quả: Cạnh 2 không được dùng để cập nhật low[v], dẫn đến low[v] không giảm xuống, và thuật toán sẽ kết luận sai rằng Cạnh 1 (và 2) là Cầu. Thực tế, chúng tạo thành một chu trình độ dài 2 nên không thể là Cầu.
Ví dụ: 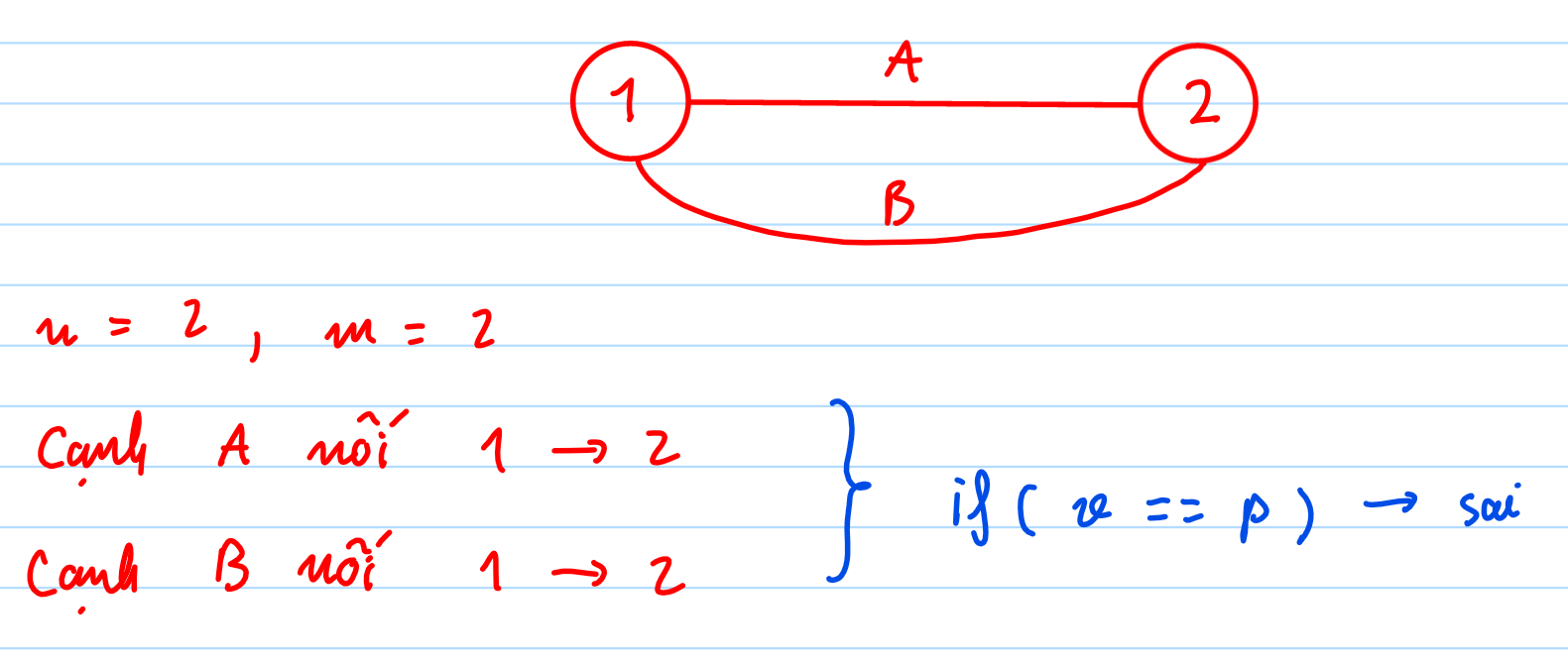
Giả sử ta DFS từ đỉnh $1$:
- Tại đỉnh 1:
disc[1] = 1, low[1] = 1. - Đi sang đỉnh 2 qua cạnh bất kỳ (giả sử cạnh $A$). Đặt cha của $2$ là $p = 1$.
- Tại đỉnh 2:
disc[2] = 2, low[2] = 2. - Duyệt các cạnh kề của $2$:
- Thấy cạnh $A$ (nối về $1$): Vì $1 == p$, bỏ qua.
- Thấy cạnh $B$ (nối về $1$): Vì $1 == p$, vẫn bỏ qua.
- Kết thúc DFS tại $2$. Quay về $1$.
- Kiểm tra điều kiện cầu cho cạnh $(1, 2)$:
- $disc[1] < low[2] \Rightarrow 1 < 2$ (Đúng).
- Kết luận: Cạnh $(1, 2)$ là Cầu.
$\Rightarrow \quad$ Sai vì ta có tận 2 đường đi giữa 1 và 2, xóa một cạnh thì đồ thị vẫn liên thông.
Giải pháp
Thay vì lưu mảng kề chỉ có đỉnh đích $v$, ta lưu một cặp pair<int, int> gồm: {đỉnh đích v, ID của cạnh}. Khi DFS, ta truyền ID của cạnh vừa dùng để đến đỉnh hiện tại, và chỉ continue đúng cái ID đó.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
typedef pair<int, int> ii;
int n, m;
const int limN = 10005;
// đổi mảng kề sang lưu pair: {v, edge_id}
vector<ii> adj[limN];
int timer = 0;
int low[limN], disc[limN];
set<int> ap;
vector<ii> bridges;
void dfs(int u, int pid) { // (đỉnh hiện tại, ID cạnh vừa đi qua)
disc[u] = low[u] = ++timer;
int child = 0;
for(const auto &[v, id]: adj[u]) {
// chỉ bỏ qua đúng cái cạnh vừa đi tới *quan trọng
if(id == pid) continue;
if(!disc[v]) {
child++;
dfs(v, id);
minimize(low[u], low[v]);
if(pid && disc[u] <= low[v]) {
ap.insert(u);
}
if(disc[u] < low[v]) {
bridges.eb(u, v);
// nếu đề bài yêu cầu in chỉ số cạnh là cầu:
// bridges_id.push_back(id);
}
} else {
minimize(low[u], disc[v]);
}
}
if(!pid && child > 1) {
ap.insert(u);
}
}
int main(void) {
cin >> n >> m;
FOR(i, 1, m + 1) {
int u, v; cin >> u >> v;
// lưu đỉnh và id cạnh i
adj[u].eb(v, i);
adj[v].eb(u, i);
}
FOR(u, 1, n + 1) {
if(!disc[u]) dfs(u, 0);
}
cout << sz(ap) << ' ' << sz(bridges);
}
Dạng 6: Thành phần song liên thông cạnh (2-Edge-Connected Components - 2-ECC) và Bridge Tree (Cây cầu)
Thành phần song liên thông cạnh (2-ECC): Là một tập hợp các đỉnh lớn nhất sao cho giữa hai đỉnh bất kỳ luôn có ít nhất 2 đường đi không chung cạnh. Hiểu nôn na đây là các vùng không chứa bất kỳ cái cầu nào.
Bridge Tree (Cây cầu): Nếu ta xem mỗi 2-ECC là một Siêu đỉnh, và giữ lại các cạnh cầu để nối các siêu đỉnh này, đồ thị ban đầu sẽ biến thành một cái Cây (không có chu trình).
- Bước 1: Dùng Tarjan tìm tất cả các cầu của đồ thị.
- Bước 2: Gom các 2-ECC bằng cách xóa tạm thời các cầu. Đồ thị sẽ vỡ ra thành các thành phần liên thông. Mỗi thành phần này chính là một 2-ECC. Đánh số ID cho từng 2-ECC (gọi là mảng
comp_id[]). - Bước 3: Dựng Bridge Tree bằng cách nối các cầu lại, thay vì nối đỉnh $u$ và $v$, ta nối
comp_id[u]vàcomp_id[v]. Lúc này ta thu được một Cây. - Bước 4: Giải quyết bài toán
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
typedef pair<int, int> ii;
int n, m;
const int limN = 1e5 + 5;
vector<ii> adj[limN];
int timer = 0;
int disc[limN], low[limN];
vector<ii> bridges;
bool isBridge[limN]; // đánh dấu ID của cạnh là cầu
void dfs(int u, int pid) {
disc[u] = low[u] = ++timer;
for(const auto&[v, id]: adj[u]) {
if(id == pid) continue;
if(!disc[v]) {
dfs(v, id);
minimize(low[u], low[v]);
if(disc[u] < low[v]) {
bridges.eb(u, v);
isBridge[id] = 1;
}
} else {
minimize(low[u], disc[v]);
}
}
}
vector<int> tree[limN]; // cây bridge tree
int comp = 0; // đếm số lượng 2-ECC
int comp_id[limN]; // lưu ID của 2-ECC mà đỉnh u thuộc về
int deg[limN]; // lưu bậc của các 2-ECC trên Bridge Tree
void dfs_comp(int u) {
comp_id[u] = comp; // gán id của 2-ECC cho đỉnh u
for(const auto &[v, id]: adj[u]) {
// nếu v chưa được gom vào 2-ECC nào và cạnh nối không phải là cầu
if(!comp_id[v] && !isBridge[id]) {
dfs_comp(v);
}
}
}
int main(void) {
cin >> n >> m;
FOR(i, 1, m + 1) {
int u, v; cin >> u >> v;
adj[u].eb(v, i);
adj[v].eb(u, i);
}
// bước 1: tarjan để thu các cạnh cầu
FOR(u, 1, n + 1) {
if(!disc[u]) dfs(u, 0);
}
// bước 2: gom các 2-ECC
FOR(u, 1, n + 1) {
if(!comp_id[u]) {
comp++;
dfs_comp(u);
}
}
// bước 3: xây bridge tree & tính bậc của các 2-ECC trên bridge tree
for(const auto &[u, v]: bridges) {
int a = comp_id[u];
int b = comp_id[v];
tree[a].eb(b);
tree[b].eb(a);
// mỗi cạnh cầu sẽ đóng góp 1 bậc cho 2 thành phần liên thông nó nối
deg[a]++;
deg[b]++;
}
// bước 4: giải quyết bài toán...
}
Cần thêm ít nhất bao nhiêu cạnh để đồ thị trở thành đồ thị song liên thông cạnh (nghĩa là mất hoàn toàn các cạnh cầu)
- Để triệt tiêu toàn bộ cầu, ta cần tạo ra các chu trình bao phủ toàn bộ cây. Cách tối ưu nhất là nối các đỉnh lá lại với nhau theo cặp (ví dụ: nối lá 1 với lá 3, lá 2 với lá 4,…).
- Mỗi cạnh thêm vào có thể xử lý tối đa 2 chiếc lá. Do đó, số cạnh tối thiểu cần thêm là $\lceil \frac{L}{2} \rceil$. Trong code C++, công thức này có thể viết nhanh là
(L + 1) / 2.